
生命不在于你活了多少日子,而是你记住了多少日子。
TOC
两万字长文:聊聊程序人生
https://mp.weixin.qq.com/s/Ctc_Gs65Q0_ekqdikP45lw
我想独立完成一个产品,技术上该怎么提升?
- 对自己的定位。个人独立完成,还是只是前端工程师、后端工程师
- 要带着问题去学习
- 发现缺失的很多知识点,怎么弥补?
- 开发中使用什么架构?
- 前端开发领域如何做技术选型?
- 后端技术栈如何抉择?
- …
- 吸收和消化为了解决具体问题而寻找的助力,内化成自己的东西 边做边学,边做边探索,然后总结,内化
怎么找到好玩的项目?
- 涉及到信息来源的问题
- 逛个两三次 hacker news 和 Github trending(or followers’s stars)、看一看各个开发者聚集的地方如Reddit相关主题贴、一些公众号
看过的或者学过的技术,如何在需要的时候找回来?
在开始看某个东西时,如果觉得未来在某个场景下会去使用它,会在笔记的对应的主题下面
比如说我在 Github 上 Star 了很多很有意思的做搜索的项目,比如说现在在 Rust 上面比较火的一个叫 meilisearch,一个叫 Sonic,这些东西我现在并不需要,所以我现在可能不见得会用到他们,但是我会放在搜索的主题下面,下次我要深入了解探索这个方向的时候,那么可能会深入探索。
不光是 Github repo,还有我在 Youtube 和 B 站上看过的视频,我都会放在专门的页面里面,做成 database。
如果多少年之后成为一个什么样的人,比如架构师,那么其实你需要做的就是你平时对你所用的东西,你感兴趣的东西,保持一份好奇心:你看到一个一个产品,就要去想这个产品背后的逻辑是什么,它的功能是怎么样实现的。如果我自己要实现的话, 这一块功能,那块功能我该用什么样的工具实现,我是自己实现,还是我拿第三方工具,我有哪些工具可以使用。这样你就可以把平日里看到的东西和你的思路串联起来。
你可以顺便多想一些,比如:如果真得要实现的话,实现到一个什么样的程度,大概花多少钱?这些东西我觉得可以反复可以在自己的脑海里面去探索,你不一定去做,因为很多时候我们遇到的东西太多了,真正值得你去深入下面去做的,一年可能也就是两三个,因为你的时间精力毕竟有限。
大部分的时候你即便不做,你可以去想,因为想本身想的过程就本身已经足够好了,因为你在思考的时候你会你会遇到问题,这个问题即便你不是去写代码解决,你也可以通过去搜索,你可以去看看别人是别人的解决方案是什么,甚至你可以对这个产品本身做 reverse engineering,去验证你的想法和人家做的是不是一样。
这些东西其实都是你在思考,你在使用 reverse engineering 的时候,你会发现这是一个问题,他没有解决好。那我该怎么样解决呢?我的方法是不是好,如果好为什么好,如果不好的话,还有什么更好的解决办法等等。这个循环往复的过程会让你的进步会很快,很多人说我在大公司里面或者在公司里面,我作为一个程序员就是一颗螺丝钉,每天能接触的事情就那么一点,那是因为很多时候有一个更广阔的世界我们可能还没有去发现。
如何定义搬砖?如何形成反搬砖的文化?
搬砖与否,因为其实我觉得很多公司的,程序员都会有这样的感慨,就是我的工作好像就是在搬砖,我的工作好像就是在被动处理产品经理的想法,他们不管最终这个产品本身会给技术带来多少的技术债,都要求必须要在规定的时间,以规定的方式来完成,这就会让大家产生一种搬砖的无力感。我觉得这是很多公司在文化上面形成的一种氛围,很多时候需要靠时间来慢慢去把它改变。
第一个对我们所做的事情,不光知其然,还知其所以然。
希望我们招的工程师,或者说我们的工程师本身要有极大的热情,想成为一个非常牛逼的工程师。怎么叫牛逼的工程师,我觉得这可能也是我们每一个技术人应该去追寻的方向,
第二个就是你要对你所做的,领域产品有强烈的主人翁的意识,ownership,就说这个东西好像就像我的孩子一样,我不知道大家有多少有孩子,你对你的孩子付出的努力跟对,别人家的孩子付出的努力,那是完全不是一个概念的。
第三个就是你的方案,你提出来的方案一定是要能够,落地,能够交付的这样一个解决方案,不是天马行空的画一个大的 picture,画一个非常酷的 architect,最后谁落地,反正我就提方案你们来落地,我们不需要这样的人。
第四个就是你要对产品中的槽点要零容忍,你的产品经理提出来的一些不合理的产品的需求,你要能给他打回去,你如果打不回去,你要能让你的经理去打回去。当然你要有充足的理由,充足的数据来说明这个事情不对。
第五个就是你对重复的任务和bug是一种零容忍的态度,我们工程师为什么会产生一种搬砖的感觉,除了刚才讲的产品上面你有很多问题,你无力去打破,还有一个在工作中我们可能有太多不停重复的任务,因为产品的需求截止日期太严苛,导致于我们只能着眼于以现在,没办法着眼于未来,没办法把这个东西抽象在一个更高的层次上面去抽象,把它做成某一个service,或者做成一个就是能涵盖包含了这个场景下面一系列场景的解决方案。
第六点是:当你成为某个领域的专家之后,你应该还是保持一个非常开放的心态,随时愿意切换你的技术栈和方法论。你不会去抗拒任何不同的思想。比如说我是一个函数式编程的粉丝,我就鄙视一切面向过程编程的所有的方法论;我是一个 react 的开发者,我就对 vue 充满了不屑和鄙视,认为它是初级程序员的专利,是那些理解不了 react 的人才会写的东西。我觉得我们程序员不应该有这样的心态,我们还是要像小王子里面说的那样,像一个小孩子一样,对什么东西都保持天然的好奇心,愿意把自己的那些「星星」都放到天空中,而不是把它包裹起来藏得很深。所以有必要的话你应该愿意去切换技术栈,切换方法论,有更好的方法,你会愿意去尝试,你会愿意去用数据来说服自己和别人:这个东西值得我们去去投入。
最后一点是你要总是能够让你的团队变得更强。你自己强还不够,你怎么样能用你自己的强大,你的影响力,无论是技术的影响力还是其他方面的影响力,让你周围的人变得更强。
工程师需要足够的时间去内化他所学的东西,去深度地考虑产品,在无数个可能的解决方案中去寻找潜在的最好的方案。
所以这是一个悖论,就是产品的需求,我明天后天下周我就要这么个东西,而很多时候不是你给我一个固定的时间,我就能把这个事情完成的。而且一旦你给了我一个固定的时间,我能采用的方案,大概率是众多的方案中不那么好的,或者说仅仅是为了解决问题而解决问题的方案。在这种时间的压力下,会导致工程师没有安全感,因为我没有时间去充分思考,我没有时间去探索,产品中有无数的bug,我没有时间去处理,我没有时间去追根跑底,我只能去一个的想办法把它绕过它,找一个「快而脏」,而不是一个终极的解决办法去敷衍。所以这需要时间,需要给工程师一个足够足够长的时间去来出来消化这个东西,让工程师足够有足够的权威,能够 push back,说这个东西我觉得不合理,你产品还没想清楚,你想清楚了之后在跟我谈,为什么我说你没想清楚,因为 case1,case2,case3 等等这些东西你没有考虑到,这些场景下我们该怎么样去处理,你没有想,所以这个东西我不能做。这是很多国内的公司还缺乏的一种文化:就是工程师来能够对产品说 NO。因为不能说 NO,所以 996甚至 007 也要把它弄完。这其实是一个是一个很折磨人的过程,这对我们工程师来讲,成长是不利的;长远来讲,短期公司得到的一些利益,长远可能也不见得那么有利。
如何处理有限的资源和产品质量之间的冲突?
大部分的决策我们要去去讨论的,是 why,为什么我们要做这件事情,这件事情做出来之后对我们的好处是什么,很多时候公司的 CEO 也会拍脑门做一些决定,不见得 CEO 做的决定都是对的,有可能其中 40% 能被我们挡掉,但剩下的60%,无论如何是不得不做的,并且它是有一些截止日期的压力,比如说你要为了某个事件,在这个事件之前,我必须要做出来某个产品的 feature,甚至某个产品来应对这个事件,因为我知道这样的时机一旦错过,可能下一个几年才能遇到的东西。这个时候我们如果说商业决策想清楚了,ROI 都算好了,那就是一个调动资源的问题,这个东西我们要评估它的 scope 有多大,有多少资源可以去使用,我们愿意为它付出多少代价,这个代价不光是内部的,还有外部的。如果自己做受限于资源无法做到更加稳定,那么可不可以找付费的供应商去做?
我觉得是当我们有一些截止日期不得不去满足的时候,我们从工程师从 CTO 或者技术骨干的角度,我们需要去考虑:有些东西我们是不是这个时刻必须要自研?就像clubhouse这样,我的核心的功能是什么,我怎么样去调配我的核心资源去做我的核心功能,把不那么核心的功能,我如果能多花一些钱就能解决的,是不是可以先把它在这个时刻用第三方服务解决?因为所有技术我一起上的话,以我现在的资源就是满足不了这个日程。所以这是一个博弈的过程,你需要跟做商业决策的那些stakeholder,比如说CEO要去博弈这些东西,你可以提出一些技术的解决方案,你说 ok 为了做这么一个东西,我需要用这些第三方服务,这些服务如果用户量级在这个程度下一个月的cost是多少。我把这个东西列出来,如果 CEO 不同意,那么我们需要这么多资源,并且我没办法保证能在日程截止之前我能完成这样的东西。这就是一个博弈的过程,需要讨价还价。不是说什么东西,别人说 ok 我就要做,我就让我手下的这兄弟们拼命地加班,没日没夜的去做这个东西。这样子长久不了,可能还会带来很多的技术债。
团队做大,人才密度是肯定下降的,不能要求人人都有主人翁的心,能不能用精细的流程来避免搬砖?
我觉得讨论就是大家和而不同,我赞同你里面的很多观点,也不赞同里面的一些观点,比如说我赞同人才密度降低这件事情,就是当你公司做大人才密度肯定,是以指数级下降,很难去避免。怎么样去尽量让下降的速度慢一些呢?我觉得一个很好的方式是通过文化来保证,你怎么样通过同一种文化的感召力去召唤那些认同你的文化的人进入到你的公司。这里相关的东西我就不展开来谈了。我稍微不太认同的是过于严谨的规则。每个公司都有一堆的规章制度,有一堆的流程,这无可厚非。
流程应该是能被自动化的东西,它不需要你去学习和遵循,工具本身就帮助你准守流程了。
比如说当你的代码提交之后,有一堆的 pre commit check,要去check你的代码风格对不对,你是不是过了静态检查,是不是过了单元测试,所有这些都通过后才会允许你提交代码。你 push 上去的时候会有一堆的 github action 去执行,去从各个维度去看你这个代码,是不是符合足够质量的,是不是破坏了现有的 code coverage 等等。这些东西不应该是写成文字去,让每个工程师去遵守的,而是就在你的工具链里,在你的公司的日常运作的过程中,自然而然地去使用规则和流程约束每个工程师的行为。而且越好的团队你会发现自动化的流程越多,就像我们写代码一样,框架是干什么的,框架就是一堆东西来限制开发者的行为,让我们有所为有所不为。为什么我们要做信息隐藏,为什么我们要去做各种各样的解耦,为什么我们要去使用各种各样的设计模式,这些其实都是流程,这些流程都是刻在我们平时开发者骨子里的流程。我觉得这些自然而然发生的流程,是最好的流程。
从另外一个角度来讲,我觉得真正的人才,如果真的把程序员看做艺术家的话,我们很难用规则去来框定它,就像截止日期件事情,如果说你毕加索在 10 天之内画出来某幅指定要求的画,那么毕加索可能画出来的,就跟我们普通的一个画师画出来的是一样的东西。梭罗在瓦尔登湖里面,讲过一句话,我特别喜欢,他说:能维持一只兔子生活的田野一定是贫瘠无比的,我觉得好的公司它就是好的公司,不好的公司它就是不好的公司,很多公司大了之后,它可能只是比小的时候没有那么,好而已,但它依旧是好的公司,好的公司很多公司它很小的时候,就跟上可能不是一个好的公司,它大了之后也一定不会是一个好的公司。
客户端软件的轮回:更好还是更糟糕?
对 SaaS 软件的愿景
- 客户端软件可以真正做到数据的 local first,云端的数据更像是一个数据的超集或者备份。
- 当数据 local first 后,对数据的各种操作(聚合,过滤,查询等)都可以利用本地 CPU 的强悍性能直接处理,而无需跨过网络。
- 协同工作,对公司(组织,团队等)内部的人员来说,由权限系统以及要同时处理某一个文档或者数据的 N 个人(设备)之间的可信共识(比如 raft concensus)处理即可 —— 这应该是绝大多数的使用场景;如果参与者不可信,可以考虑使用不可信共识(比如 BFT consensus)。
- 如果能进一步,刨除服务器(或者服务器仅仅做备份的功用),完全去中心化,那将更加美妙,不过在资本市场这个故事很难讲好(需要新的估值模型)。
想象力,工程方法以及取舍
https://mp.weixin.qq.com/s/3OlEBl9ybiNQ2s328DVCEQ
如何保证 single source of truth(以下简称 SST)?
 在分布式系统里,能被正确用作 SST 的只有事件(event,或者 operation)。从整个应用的角度,主流的思想是把广义的数据库(RDBMS,DDBMS,kv store,object store)作为 SST,这无可厚非,但我们不能因此推断出数据库就等同于 SST,或者得出结论没有数据库就没有 SST。从数据库的角度看,数据库里存储的数据(状态)并不是 SST,数据库的 SST 是一个个的 op —— 你可以理解为增删改的动作 —— 它们就是一个个事件。这是最原始,也最容易在集群中复制的信息,数据库的状态可以通过这些 oplog/WAL 按顺序迭加恢复出来。
在分布式系统里,能被正确用作 SST 的只有事件(event,或者 operation)。从整个应用的角度,主流的思想是把广义的数据库(RDBMS,DDBMS,kv store,object store)作为 SST,这无可厚非,但我们不能因此推断出数据库就等同于 SST,或者得出结论没有数据库就没有 SST。从数据库的角度看,数据库里存储的数据(状态)并不是 SST,数据库的 SST 是一个个的 op —— 你可以理解为增删改的动作 —— 它们就是一个个事件。这是最原始,也最容易在集群中复制的信息,数据库的状态可以通过这些 oplog/WAL 按顺序迭加恢复出来。
在 web app 里,我们在更高的层次实现业务逻辑,因此可以把数据库里的数据(状态)作为 SST。因为我们知道,不管数据库的实现是强一致性,还是弱一致性,它们都能保证最终一致性(当更新停止时,最终所有的数据库节点都能聚合到同样的数据)。而保证了最终一致性的数据库,就有资格被当做 SST。
当我们把数据下放到每个客户端时,每个客户端其实可以被看做所有客户端维护的数据库系统的一个节点。上图中一个个 list,就是状态。我们的目标是这些状态的最终一致性。而根据数据库的思路,SST 是事件 —— 用户对 list 的各种操作。这些事件主要有:
- 在 list 里添加一个新的数据项
- 修改一个已有的数据项
- 删除一个已有的数据项
- 移动一个已有的数据项
我们如果能在所有参与的节点中确保所有的事件都被正确扩散,那么,通过迭加这些事件,我们可以得到最终一致的状态。
通过迭加这些事件,得到最终一致的状态?
「不可能先生」的头几个质疑:
- 网络不稳定,事件有可能丢;
- 事件到达不同客户端的顺序可能不一致。
假设我们有办法做到不丢事件,并且保持同样的事件顺序。所有的客户端的状态都可以被描述成(S 代表状态,E 代表事件,+ 代表事件叠加):
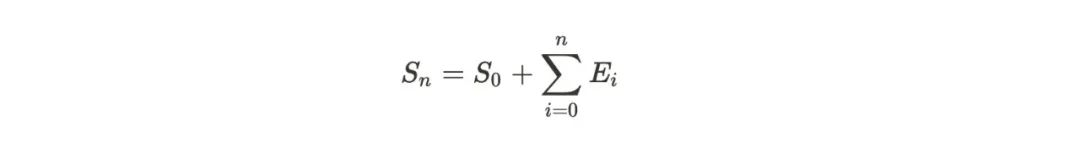
不丢事件如何保证?
- 如果用中心化的解决方法,可以引入一个 message queue(其实变相引入了 raft 这类 CFT 共识算法)
- 如果去中心化的解决方案,需要引入类似区块链技术使用的共识机制来确保顺序(区块链的区块,实质上是一个全局时钟,它用来提供一致的事件顺序
要求所有的客户端都看到顺序一致的事件?
- 事件到了服务器之后被排序,客户端需要按照服务器要求的顺序生成状态。 不仅仅要支持迭加的操作(+),还需要支持回滚(-) 产生了新的问题🙋,如何解决冲突?先按下不表
如何确保不同客户端看到的数据一致?
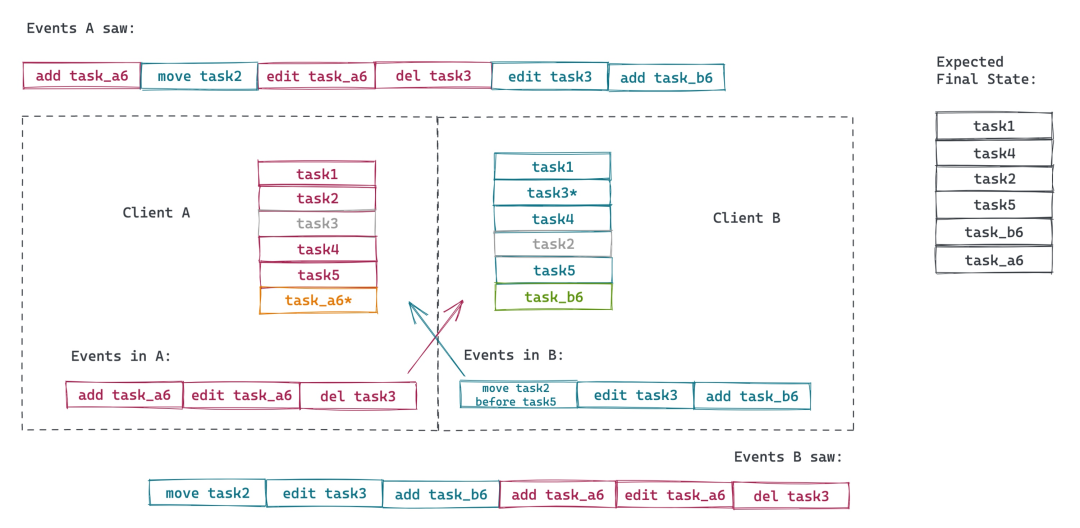
- list 里所有数据都有全局唯一的 id。这里我们用 task1, task2, …。数据的 id 中包含客户端的 id。
- 每个数据有一个指针,指向前一个数据,以便于我们定位其相对位置,移动数据的时候,我们需要更新这个指针来保持数据的相对位置。
- id 之间是可以比较的,比如上图 A 和 B 都在 task5 之后插入了一个新的 item,我们定义 b6 > a6 的比较关系(这个无所谓,也可以 a6 > b6),这样,task_b6 的前一个数据是 task5,而 task_a6 的前一个数据 task_b6。
如何解决冲突?
幸运的是,目前已经有很多已知的算法来解决在线协作的问题。其中典型的两种算法是 OT(Operational Transformation)和 CRDT(Conflict-free Replicated Data Types)。
OT
OT 是一个思路简单,但实现复杂的算法,其基本思想是,不同的节点在收到不同顺序的事件(在 OT 下是 operation)时,将后续的 OP 进行 transform,使其能够分别聚合出相同的状态,如下图:
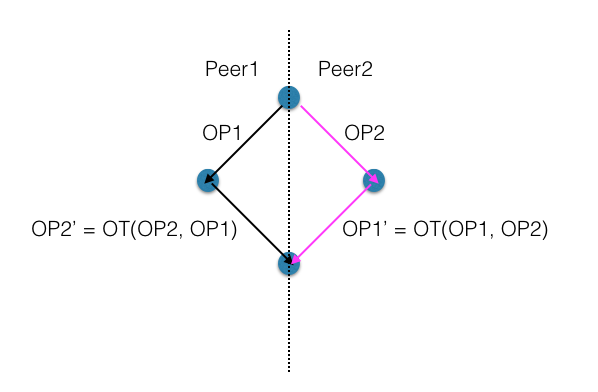 那么谁来做这个 transformation 呢?服务器。Peer1 和 peer2 在执行了自己的操作 OP1 和 OP2 后,将操作通过服务器发送给对端,服务器根据收到的 OP,可以确定一个唯一的顺序,也就是能够确定一个唯一的最终状态,然后服务器再根据每个客户端的不同情况,对将要转发给客户端的 OP(对于 pper1 是 OP2,对于 peer2 是 OP1)进行相应的 transformation,然后发送之。这样,客户端在接收到修改后的 OP 后,可以生成和服务器一致的状态。
那么谁来做这个 transformation 呢?服务器。Peer1 和 peer2 在执行了自己的操作 OP1 和 OP2 后,将操作通过服务器发送给对端,服务器根据收到的 OP,可以确定一个唯一的顺序,也就是能够确定一个唯一的最终状态,然后服务器再根据每个客户端的不同情况,对将要转发给客户端的 OP(对于 pper1 是 OP2,对于 peer2 是 OP1)进行相应的 transformation,然后发送之。这样,客户端在接收到修改后的 OP 后,可以生成和服务器一致的状态。
CRDT
如果说 OT 是一个中心化的解决方案,那么 CRDT 则是一个非中心化的解决方案。
继续放飞想象力
我们还以 Notion 为例。一个 Notion 用户可以有多个 workspace。如果数据全部放在本地,以 CRDT 的形式保存成文件,那么一个 workspace 在本地可以存储在一个目录下。根目录下可以存放这个 workspace 下所有用户的基本信息,用一个 automerge 下的 table(姑且简称 amt),存为 user.amt。这个文件里的用户信息,当前用户只能修改自己那一行;workspace 的 owner / admin 可以增删改。用户信息之外,我们还需要一个 permission.amt,存储每个用户在不同上下文下的角色。这样,我们可以使用 oso[7],通过 RABC 来处理授权。user/permission 相当于 workspace 的 metadata,其它的 metadata(比如配置)我们放下不表。
workspace 承载的是用户的数据。对于目录树,我们可以用一个 workspace.amt 来保存目录树的 CRDT 数据。目录树下有子目录或文件,子目录下有更深的目录或者文件。和文件系统的目录树类似,这里的文件我们放一个引用,然后文件本身有单独的 amt,如 doc4.amt。整个 workspace 的结构如下:

当用户在 UI 上对某个文档做了一个改动后,这个改动的 change 会从前端界面发送到应用的后端(非服务器的后端)。在应用的后端,automerge backend 对改动进行处理后,会生成一个 patch,提交回 frontend 去 apply。同时,这个改动通过网络(可以是服务器中转,也可以是 p2p 网络)传播出去。比如我们可以使用 libp2p 下的 gossipsub,在某个 topic 下传播。topic 可以是某一个 workspace,只有在这个 workspace 下的用户才能加入到这个 topic 下。当客户端 B 收到这个 syncMessage 后,它会提交给 automerge backend,生成 patch,提交给 frontend apply。
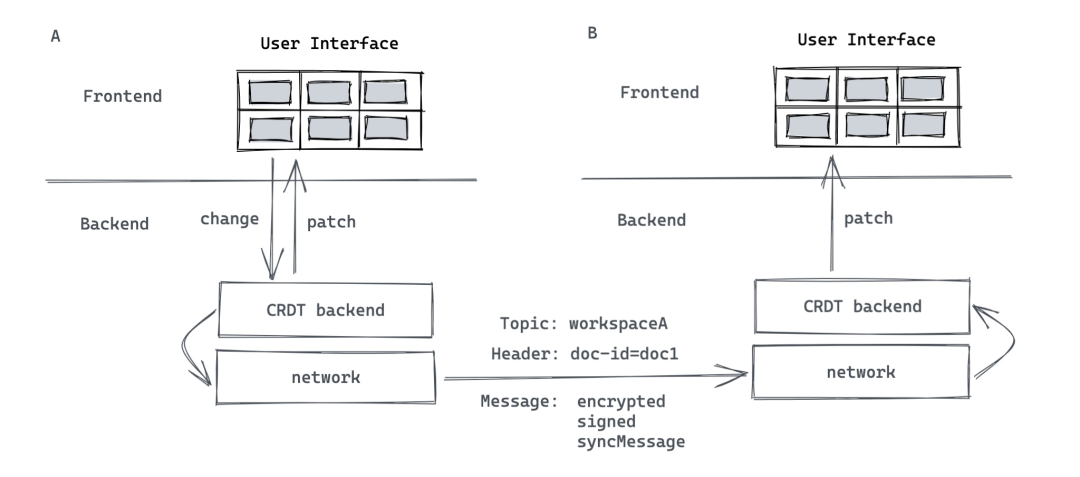
如果整个系统中有服务器中转事件,那么服务器可以 tap 出一份 amt 作为备份。一个新加入的客户端可以迅速从服务器拿到整个历史记录,进而参与到 workspace 的协作中。如果整个系统中没有服务器中转事件,使用的是 p2p 网络,那么服务器可以充当 p2p 网络中的一个节点,tap 出 amt 做备份。新加入的客户端节点可以从其任一个邻居那里要完整的数据。
取舍(Trade off)
CRDT的好处:
-
- local first:数据存储到本地,即时的响应速度,允许离线处理。
- 可以不依赖服务器而在客户端提供各种各样的数据访问的方式(filter, aggregate, projection, gorupby 等等),甚至,可以提供 API 让本地数据很容易被 pandas 等工具使用。
- 即便使用服务器中转,其服务器资源的开销相对要小很多,对于一个大型的项目,节省的资金会很可观。
缺点:
- 随着时间本地数据会增长得越来越大,由于存储着数据的全集,这个数量可能会很可观(可以有一些优化,比如用户上传的图片,视频这样的静态资源可以放在 S3,本地只放链接,访问时再获取 presigned url),所以,这种方法很可能不适合在浏览器端使用。
- 整个系统的复杂度比大家熟悉的 web 技术栈要大很多。
- 技术栈小众,很难找到合适的工程师(当然,这也意味着一旦找到,必然是优秀的工程师)。
- 市场上缺乏成功的先例(我指专门处理列表和文档这块的 sequence CRDT,其实 CRDT 在很多软件中已经得到了广泛使用,比如 phoenix framework,redis 等)。
激荡二十年:HTTP API的变迁
这篇文章所介绍的 API 的变迁,特指客户端和服务器之间运行的 HTTP API。一切其他协议的 API(如 TCP),或者服务器之间的 HTTP API(如 gRPC),不在深入讨论之列。
2005年之前:API 的狂野西部
早期的互联网是非常狂野的,没有所谓前端后端之分。PHP 开发者可以把从处理用户的 HTTP 请求,连接 mysql,组装 SQL 进行查询,将查询结果转换成 HTML,一路到 HTML 响应返回给用户的整个业务逻辑放在一个(或者若干个)如意大利面条般的脚本中。

早期微软把太多的赌注放在了曲高和寡的 WSDL(以及服务发现协议 UDDI)上,其主打做 web 开发的 ASP.Net 一直不温不火,根本无法与红遍天的 PHP 相提并论。在 2005 年之前,可以说,(在 web 世界里),PHP 是宇宙中最好的语言。
2005-2010:从混沌到有序 — Ruby on Rails 横空出世
rails 是一个足以载入史册的框架:它把软件开发中的很多非常有益的概念、模式和思想(包括但不限于 ORM,CoC,MVC 等)糅合在自己体内,构建了一个强大同时非常易用的 web 开发系统。在 rails 下,哪怕你是个 web 开发的小白,在学习了 rails 的开发文档后,也能很快撰写出一套让很多 web 开发老鸟艳羡的系统。在 rails 诸多创新之中,要数 ActiveRecord 最为经验,它以简洁优雅的表述,颠覆了人们传统上对数据库的认知,并且几乎凭借一己之力,把 ORM 捧上了神坛。
随着 rails 一起成长的还有 XMLHttp object (俗称 Ajax)的标准化,以及 JSON 的广泛使用。其中,Google 通过其旗下的 gmail / google maps 大大促进了人们对 Ajax 的认知,而 PHP5 和 rails 3 则将 JSON 在广大开发者中推广开来,使其逐渐取代笨拙低效的 XML。有意思的是,Ajax 最初是 Asynchronous Javascript And XML,JSON 普及后,这个 XML 再也没人提及。
由 rails 刮起的 ORM 之风愈演愈烈,它几乎成为了 web 开发者访问数据库的唯一标准。渐渐的,存储过程(stored procedure / function)被雪藏,触发器(trigger)被遗忘,数据库复杂而迷人的权限管理被弃之不顾,取而代之的是用一个几乎具有 root 权限的用户来连接数据库,而权限的管理全部被前移到了应用层。这和 ORM 所倡导的「一套代码处理多种数据库」有莫大的联系。事实上,ORM 带给大家切换数据库的好处,可能仅限于开发环境用 sqlite,生产环境用 postgres 这样的便利。但从管理的角度,ORM 让开发者绕过 DBA(或者干脆不要 DBA)进行快速开发,对于小型项目,可以高效开发,且不需要构建数据库领域的专有技能,毕竟培养一个 web 工程师,两三个月的训练营就可以让一个素人很好掌握开发框架,进行「高效」 CRUD 开发;而培养一个合格的 DBA,需要整个计算机体系知识的沉淀。
2010-2015:移动互联网 — API 飞上枝头变凤凰
由于移动应用拥有自己的 UI 层,不像浏览器那样,UI 层是由服务器返回的 HTML 渲染出来,因而移动端和服务器之间有着强烈的对简洁高效且标准化的 API 层的需求。在这种需求的催生下,REST(Representational state transfer)这个当时已不新鲜的概念渐渐从象牙塔走入了工业界。人们发现,与其自己随机指定一套 HTTP API 的规约,不如遵循 HTTP/1.1 规范,让 API 的表述和规范靠拢。这个时期,各个框架要么开始内建对 RESTful API 的支持,要么在框架之上,独立出一套专门为 API 优化的框架,比如 2012 年就比较成熟的 django REST framework:
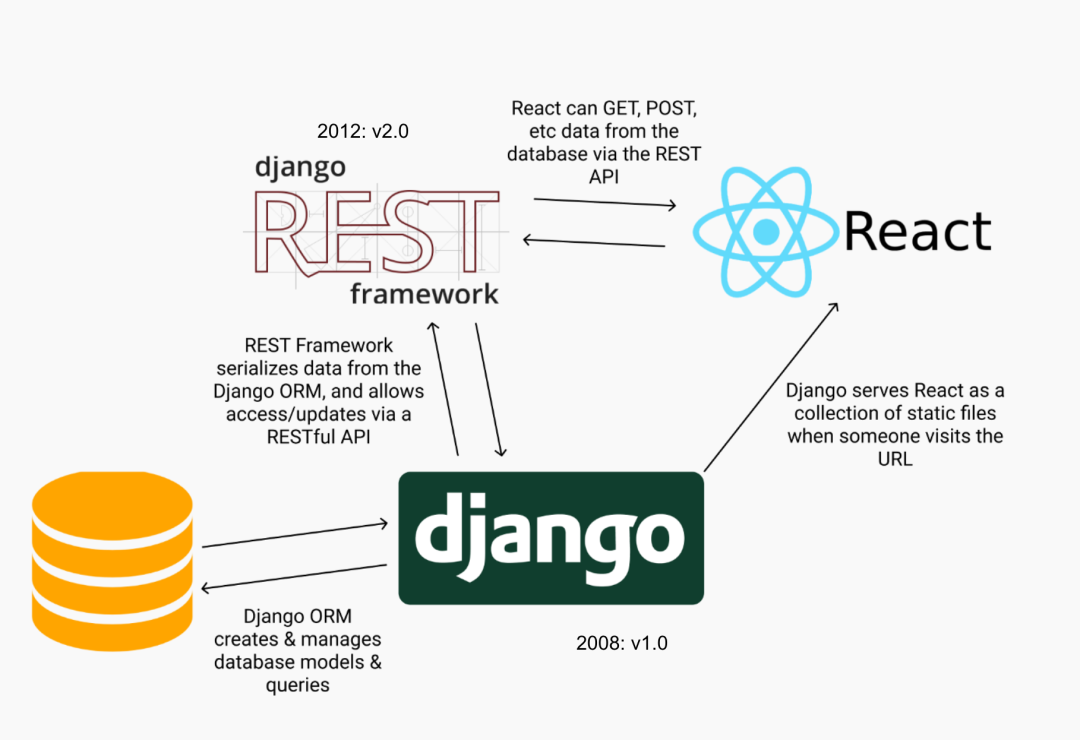
这个时期,如雨后春笋般绽放的众多 REST API framework 给开发者带来的巨大好处是,你即便不掌握 HTTP/1.1 协议的细节,也可以做出像样的 API,来处理客户端和服务器间的交互。
然而,并不是所有的 API 框架都足够严谨,足够遵循协议本身。很多 API 框架,在处理复杂的协议流程时,要么会有自相矛盾的处理,要么把这些细节完全交由开发者处理。然而,你如何保证只热衷于进行 CRUD 的开发者能够正确使用 ETag 作为乐观锁(optimistic locking)进行条件更新(conditional update)呢?
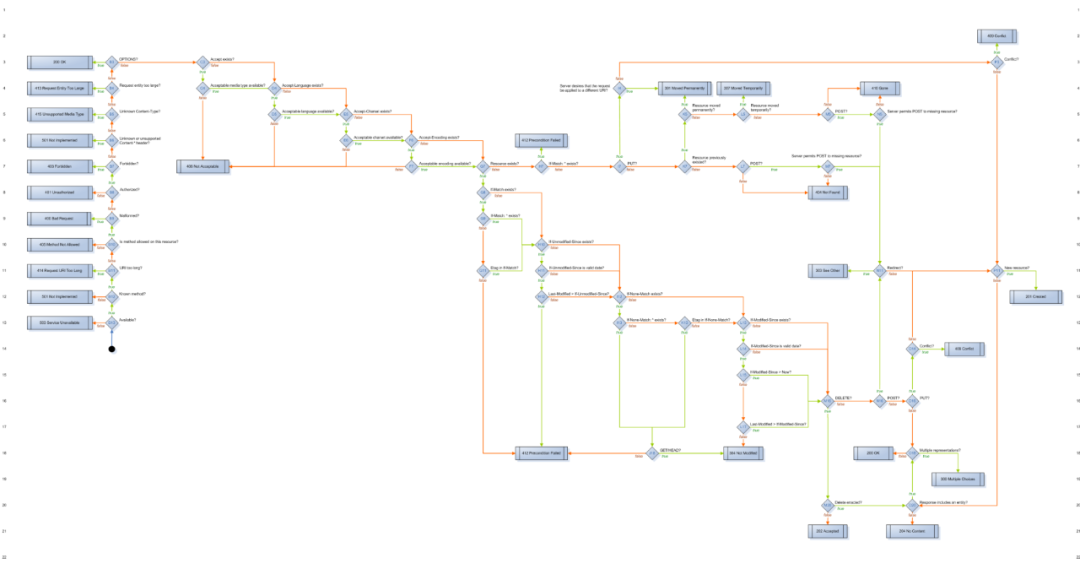
在 web 世界不为人知的角落,Erlang 的 webmachine 尽着最大的努力来确保 API 的处理符合 HTTP 协议。得益于 erlang 强大的 pattern matching 的能力,webmachine 在内部构建了一张庞大的决策树,涵盖了 API 处理的每一个细节,连每个错误返回的状态码都精益求精。
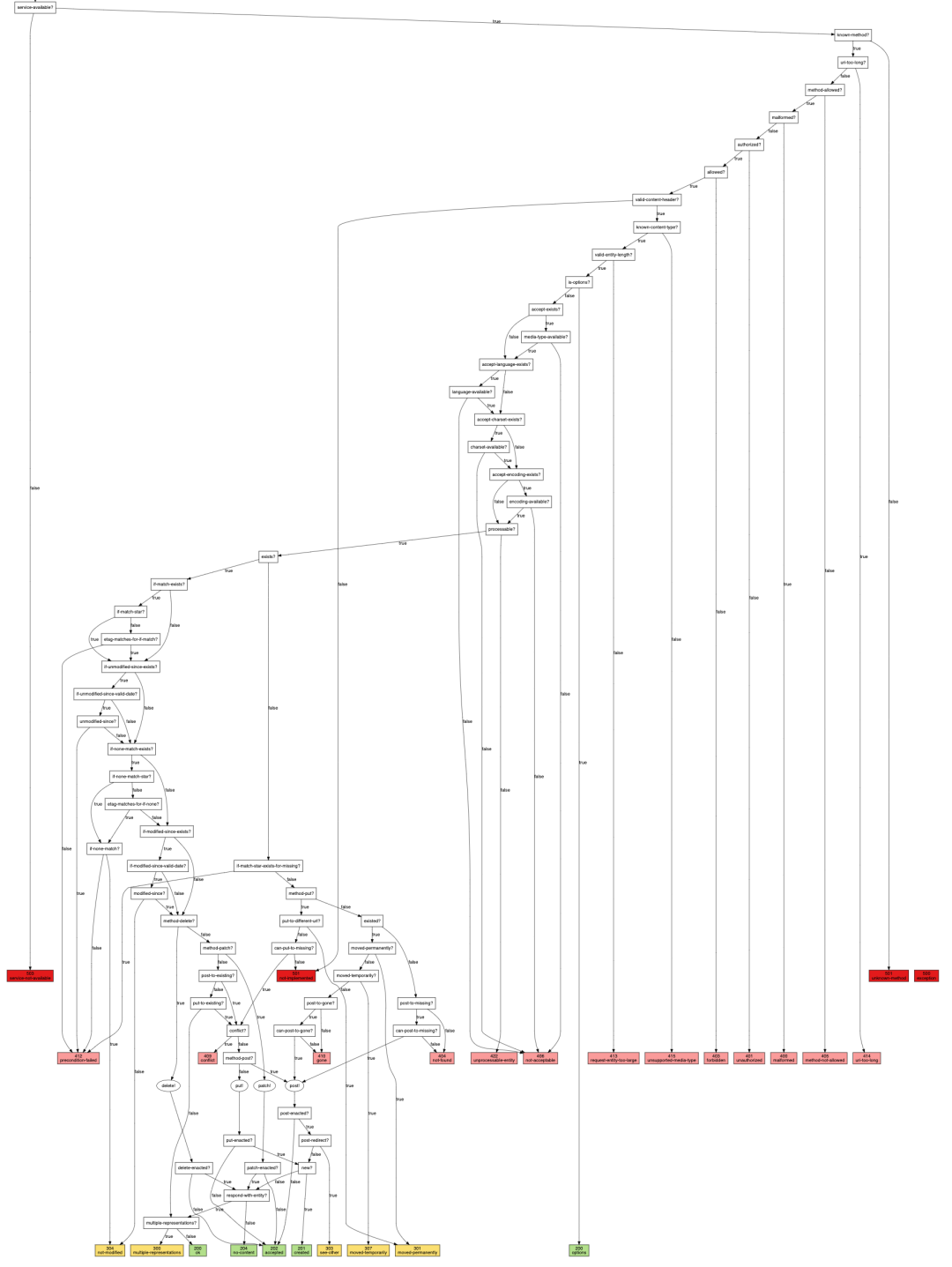
另一个小众语言 clojure 的小众框架 liberator 也把 webmachine 的这一思想学了过去,并发扬光大:
然而,移动互联网不是小众语言和小众框架的战场。何况,API 毕竟是客户端和服务器共同的约定,在那个年代,服务端的严谨会给客户端带来不小的困惑:相较于 412 Preconditional failed 而言,客户端工程师更钟情于一招鲜吃遍天的 400 Bad request
2015-2020:类型安全 — 新的共识
2015 年,facebook 首先用开源的内部项目 GraphQL 向业界打出了意图取代 RESTful API 的一记重拳。GraphQL 从输入和输出入手,在 HTTP 协议之上定义了一套查询语言 —— 客户端和服务器之间需要定义好支持的 query / mutation / subscription 的 schema,以及输入和输出数据结构的 type。
GraphQL 提出了一个看待 API 的全新视角:客户端使用者可以根据需要灵活定义他们想查询的数据,而不需要看服务端老爷们的脸色。在固执的 RESTful API 的原教旨主义者眼里,API 应该严格对应资源,因而一个 app 页面如果包含三种不同的资源,那么它就要访问三个不同的 API 来获得结果。对客户端来说,这额外多了两个浪费用户宝贵等待时间的 roud trip,为什么不能一个查询就获得我想要的数据,且仅包含我想要的数据呢?
这个想法很有创意,但它忽视了灵活性带来的可能并不值得的复杂性。GraphQL 的理想情况一直没有很好地达成,因为服务端不可能为一个多层随意嵌套的查询去准备数据。同时 GraphQL 还有其他很多设计上考虑不周的问题,其中最让人诟病的是,对 HTTP 协议的无视,也就导致整个 HTTP 生态和 GraphQL 工作地很别扭,还有查询时 n+1 的问题(data loader 只是个特定场景的解决办法)。
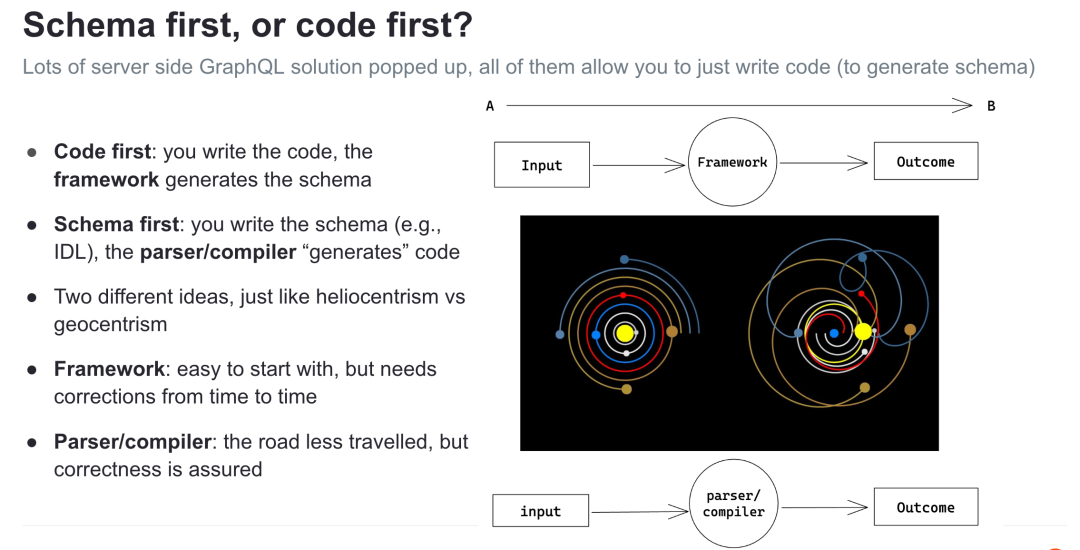
大部分支持 GraphQL 或者 OpenAPI 的框架遵从程序员的本性,让你可以专注于写代码,顺带生成相应的 schema。这是典型的 code first 的思维。
而 schema first 的代表要数 gRPC —— 你撰写 protobuf 定义,相应的编译器会替你生成代码。
这两种方案的背后,实际上是框架思维和编译器思维的较量。
2020-至今:低代码时代 — API 何去何从?
postgREST
以数据库 schema 为单一数据来源,由内及外地生成 API schema,甚至 API 本身。
使用 postgREST,开发者只需正常定义数据库中的表,视图,函数,触发器等,并为它们的使用权限赋予相应的角色即可。postgREST 可以根据数据库的 infoschema,掌握详细的 metadata,并用这些 metadata 来验证 API 的输入,也就是 Request,如果验证通过,会根据 Request 生成相应的 SQL 查询,然后把结果序列化成客户端需要的结构,以 Response 返回。举个例子,对于这样一个 API 请求:GET /people?age=gte.18&student=is.true ,postgREST 会验证数据库中包含 people 表或者视图,并且其含有 age / student 这两个字段,前者是整型,后者是布尔型。如果一切符合,并且用户具备 people 表或者视图的 SELECT 权限,那么它就会生成 select * from people where age >= 18 and student = true 这样一条查询,返回相应的 JSON(默认客户端 accept: application/json)。
postgREST 还跟 postgres 的 RLS(Row Level Security)深度绑定,来解决用户个人信息安全访问和更新的需求。比如用户只能修改自己的帖子,但可以读别人的帖子这样的业务需求,如果没有 RLS,很难从数据库级别直接安全地实现。
Hasura
Hasura 试图回答一个问题:有没有可能把 GraphQL 的 query 一对一转换成 SQL 语句?
我们知道 GraphQL 查询会被编译成 Graph AST,而 SQL 查询会被编译成 SQL AST,所以上述那个问题就变为:Graph AST 可以被安全高效地转换成 SQL AST 么?
思考,问题和方法
人的成长是有诱因的,但不外乎得到他人指点,和自己开悟两种情况。
孔子说三十而立,立的是什么?是立德、立功、立言这三不朽么?还是小家子些的,立身,立家,立业?每个在奔四路上的人都会有自己的体味和解读。但不容置疑的是,三十岁往上,要渐渐形成自己的思想和方法论
而在 Joe 的眼里,erlang 其实没有什么神秘的,仅仅六个函数就能涵盖它的全部:spawn,send,receive,register,whereis,self。
仔细想想,它简单地可怕,就像物理学的大一统理论一样,试图从纷繁复杂中跳脱出来,回归本源。更可怕的是,这六个函数不仅仅涵盖了 erlang,似乎也可以解释软件领域里的很多系统 —— 它们无所不在,在系统里面的意义就像原力之于星战。
- spawn:创建一个资源。对于 erlang,这资源是 process;对某个 service,是 service 本身。
- send / receive:给资源发指令和接受指令。对于 erlang,这指令是 message,封装成 erlang term,走的是 IPC/RPC;而对某个 http service,指令是 request,封装成 json / msgpack / protobuf,走的是 http / http2。
- register / whereis:资源怎么注册,怎么发现。对于 erlang,这是 process 在 name register 的注册和发现;对于某个 service,可以是 Consul / DNS。
- self:返回自己的 identity。在 erlang 里,这是 process 找寻自我的方式;在 micro service 的场景下,每个 service 隐含着有自己的 identity。
我喜爱 Joe,和我喜欢 Rich Hickey 一样,他们在传播知识的同时,传播他们自己对事物独特的理解和思考。
谈谈边界
我们做系统,做设计,很多时候其实就是在明确边界。函数和函数要明确边界,模块和模块要明确边界,服务和服务要明确边界,应用和应用要明确边界。明确边界能让我们的代码逻辑严谨,条理清晰。边界之内,对于外部世界,是个黑盒,一切物质的非物质的交换都只能在边界上通过已知的接口(interface)完成;同时来自外部世界的 impure data 在这里被校验(validate),过滤(filter),变换(transform)成为符合内部世界运行的 pure data。
函数的边界是其 signature,一个函数的 signature 由其名字,输入参数及其类型,返回值及其类型共同构成。外部访问者无需了解函数的实现,通过调用函数来执行其代码。函数类似于生物体中的细胞。
随着软件日益复杂,若干函数被组织成类,或者模块,来完成某个功能,从此,作用域的概念开始深入人心。有些函数承担对外的接口,他们是 public 的,有些完成内部功能,他们是 private 的。类或者模块的边界由文件名,类名(模块名)和公有方法组成。类或者模块类似于生物体中的组织。
进一步地,若干类/模块聚合起来,提供某个服务,就形成了组件(component)。组件的表现形式往往是一个目录(或者子目录),它有自己的抽象接口(start / stop / process_message / … )。组件的边界由组件所在的目录,抽象接口和 public class / module 组成。组件类似于生物体的器官。
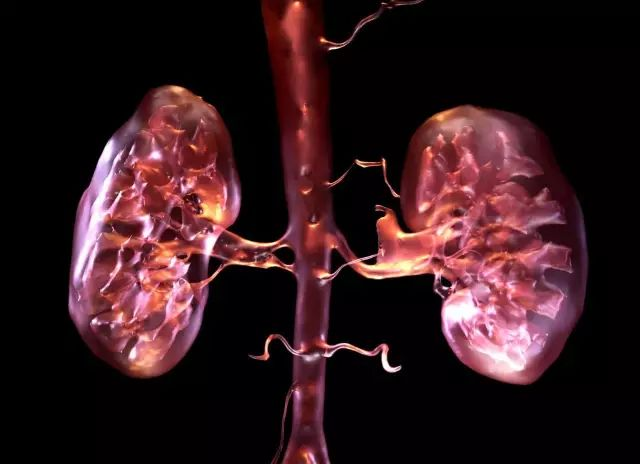 生物体和软件很相通的一点是它们也拒绝 single point of failure。上图是人类的肾脏器官,经典的 active-active cluster 设置。那些卖肾买 iPhone 4 或者 iPhone 6P 的同学至今还活蹦乱跳的一个原因是,即便一个肾没了,另一个也会负担起所有的流量,保证体液循环畅通无阻(当然,最大承载的流量打了折扣)。
生物体和软件很相通的一点是它们也拒绝 single point of failure。上图是人类的肾脏器官,经典的 active-active cluster 设置。那些卖肾买 iPhone 4 或者 iPhone 6P 的同学至今还活蹦乱跳的一个原因是,即便一个肾没了,另一个也会负担起所有的流量,保证体液循环畅通无阻(当然,最大承载的流量打了折扣)。
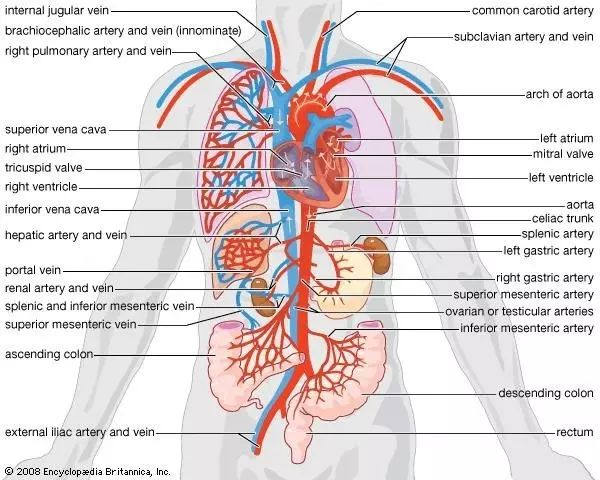
就像乐高积木一样,进一步,我们可以把若干组件聚合起来,实现某个目的,这就构成了应用(application)或者子系统(sub-system)。应用的表现形式是一个由若干目录组成的项目。它的边界由它的名字,使用的资源(比如端口)以及应用的入口(比如 main 函数)组成。应用类似于生物体中的系统,比如下图的循环系统:
再往上,若干个应用组成了一个解决方案(solution),为某个业务目的保驾护航。解决方案就像一个完整的生物体,它的边界大到一份复杂的商业蓝图,小到 iOS 上的一个工具软件。类比于一个完整的生物体,当我们做一个解决方案时,我们要界定它的子系统,哪些应该是:
- dummy system - 就像我们的呼吸系统一样,风雨无阻,就连睡觉也会自动工作。我能想到的例子有,日志系统,监控系统,错误报告系统等。
- intelligent system - 就像我们的免疫系统一样,根据外部的变化而应对之。这样的 system 一般在 behavior based reaction system 中,如 firewall,dynamic user classification 中使用。
- C&C system - command and control,就像我们的大脑一样,发号施令,控制整个机体的行为。前几年 热络的 SDN 中的 S 就是这个东东。
Concurrency
Concurrency VS. Parallelism:
- Concurrency同时处理很多事情;Parallelism同时做很多事情;
- Concurrency关于结构;Parallelism关于执行;
- 以并发方式构建解决方案,可免费获得并行性。
常见并发模型: lock based concurrency,locks/semaphore/mutex。 产生的问题:
- 需要太多锁
- 容易产生错误的锁
- 需要保证锁的顺序
- 错误恢复
- 能以组合
CSP。顺序执行;通过channels同步通信;交替复用通道
Do not communicate by sharing memory; instead, share memory by communicating. — Effective Go
Actor Model。称为进程的轻量级对象;没有共享数据;消息保存在mailbox中并按序处理。与CSP相比:
- 没有匿名的processes
- 点对点通信
- 消息传递是异步的
- 传递大数据时性能较差
STM:Future(Promise/Observable…)
Future: An object that hold data which is not resolved immediately.
GitHub - tc39/proposal-observable: Observables for ECMAScript
技术债:人的因素
在维基百科中,技术债是这么定义的:
Technical debt is a concept in software development that reflects the implied cost of additional rework caused by choosing an easy (limited) solution now instead of using a better approach that would take longer.
所以我们可以把技术债看做是一种捷径 —— 一种带来短期利益(交付期更短)但需要未来花费更多时间弥补的技术捷径。
技术债分成几个部分:1) 架构和设计上的技术债 2) 代码实现层引入的技术债 3) 软件测试的技术债 4) 文档技术债。
开发者是否对已有系统有足够的了解,往往决定了这个功能的质量。
正因为人的因素在软件开发的各个环节中如此重要,为了减少不必要的技术债的产生,最好的方法是不断招募足够优秀的人才,进行合适的培训,并且给予他们最大的上下文来处理要处理的问题;同时,不断优化和自动化开发流程,使得每一次新的 commit,引入的熵尽可能少。