
- 小贴士:如何制作快速加载的 HTML 页面 - 学习 Web 开发 | MDN
- 渲染页面:浏览器的工作原理 - Web 性能 | MDN
- 渐进式加载 - 渐进式 Web 应用(PWA) | MDN
- Web 性能 | MDN (mozilla.org)
浏览器从URL到网页的过程:
- 浏览器使用HTTP协议或者HTTPS协议,向服务器请求页面
- 把请求回来的HTML代码经过解析,构建成DOM树
- 计算DOM树上的CSS属性
- 最后根据CSS属性对元素逐个进行渲染,得到内存中的位图
- 一个可选的步骤是对位图进行合成,这会极大地增加后续绘制的速度
- 合成之后,再绘制到界面上
从HTTP请求回来之后,这个过程并非一般想象中的一步做完再做下一步,而是一条流水线。 从HTTP请求回来,就构成了流式的数据,后续的DOM树构建、CSS计算、渲染、合成、绘制,都是尽可能地处理前一步的产出:即不等到上一步骤完全结束,就开始处理上一步的输出,这样在浏览网页时,才会看到逐步出现的画面。
网页请求从 HTML 文件请求开始。服务器返回 HTML——响应头和数据。然后浏览器开始解析 HTML,转换收到的数据为 DOM 树。浏览器每次发现外部资源就初始化请求,无论是样式、脚本或者嵌入的图片引用。有时请求会阻塞,这意味着解析剩下的 HTML 会被终止直到重要的资源被处理。浏览器接着解析 HTML,发请求和构造 DOM 直到文件结尾,这时开始构造 CSS 对象模型。等到 DOM 和 CSSOM 完成之后,浏览器构造渲染树,计算所有可见内容的样式。一旦渲染树完成布局开始,定义所有渲染树元素的位置和大小。完成之后,页面被渲染完成,或者说是绘制到屏幕上。
HTTP协议
浏览器要做的事就是根据URL把数据取出来,取回数据使用的是HTTP协议,实际上这个过程之前还有个DNS查询。
HTTP标准由IETF组织制定,跟它相关的标准主要有两份:
HTTP协议是基于TCP协议出现的,对TCP协议来说,TCP协议是一条双向的通讯通道,HTTP在TCP基础上,规定了Requset-Response的模式。这个模式决定了必定是由浏览器端率先发起的。
大部分情况下,浏览器的实现者只需要用一个TCP库,甚至一个现成的HTTP库就能搞定浏览器的网络通讯部分。HTTP是纯粹的文本协议,它是规定了使用TCP协议来传输文本格式的一个应用层协议。
下面我们使用纯粹的TCP客户端手动实现HTTP
首先运行telnet,并连接到baidu.com主机,在命令行输入如下内容
telnet baidu.com 80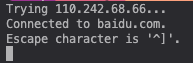
这个时候,TCP连接已经简历,输入如下字符作为请求:
GET / HTTP/1.1
Host: baidu.com
按下两次回车,可收到服务端请求:
HTTP/1.1 200 OK
Date: Tue, 01 Aug 2023 09:47:39 GMT
Server: Apache
Last-Modified: Tue, 12 Jan 2010 13:48:00 GMT
ETag: "51-47cf7e6ee8400"
Accept-Ranges: bytes
Content-Length: 81
Cache-Control: max-age=86400
Expires: Wed, 02 Aug 2023 09:47:39 GMT
Connection: Keep-Alive
Content-Type: text/html
<html>
<meta http-equiv="refresh" content="0;url=http://www.baidu.com/">
</html>
这就是一次完整的HTTP请求过程了,可以看到在TCP通道中传输的,完全是文本。
在请求部分,第一行被称作request line,它分为3部分:HTTP Method、请求路径、请求的协议和版本。
在响应部分,第一行被称为response line,也分为3部分:协议和版本、状态码和状态文本。 紧跟在request line或response line之后的,是请求头/响应头,这些头由若干行组成,每行是用冒号分割的名称和值。
在头之后,以一个空行(两个换行符)为分割,是请求体/响应体,请求体可能包含文件或者表单数据,响应体则是HTML代码。
HTTP Method
首先看request line里面的方法。这里的方法与编程中的方法意义类似,表示此次HTTP请求希望执行的操作类型。方法有以下几种定义:
- GET
- POST
- HEAD
- PUT
- DELETE
- CONNECT
- OPTIONS
- TRACE
浏览器通过地址栏访问都是GET方法,表单提交产生POST方法。 HEAD与GET类似,只返回响应头,多数由JavaScript发起。 PUT和DELETE分别表示添加资源和删除资源,但这只是语义上的约束。 CONNECT多用于HTTPS和WebSocket OPTIONS和TRACE一般用于调试,多数线上服务都不支持。
HTTP Status code & Status text
常见的HTTP状态码有以下几种:
- 1xx:临时回应,表示客户端请继续
- 2xx:请求成功
- 3xx: 表示请求目标有变化,希望客户端进一步处理
- 301 & 302: 永久性或临时性跳转
- 304: 客户端缓存没更新
- 4xx:客户端请求错误
- 403: 无权限
- 404: 请求页面不存在
- 5xx:服务端请求错误
- 500: 服务端错误
- 503: 服务端暂时性错误,可重试
对前端而言,1xx系列的状态码非常陌生,原因是1xx的状态被浏览器HTTP库直接处理掉了,不会让上层应用知晓。 2xx系列最熟悉的是200,这通常是网页请求成功的标志。 3xx系列比较复杂,301和302两个状态表示当前资源已被转移,不过一个是永久转移一个是临时转移。实际上301更近似报错,表示客户端下次别来了。 304产生的前提是:客户端本地已经有缓存的版本了,并且在Request中告诉了服务器,当服务器通过事件或tag发现没有更新的时候,就会返回不含body的304状态。
HTTP Head
HTTP头可以看成一个键值对。原则上HTTP头也是一种数据,我们可以自由定义HTTP头和值。在HTTP标准中定义了完整的请求、响应头。
先来看看Request Header。
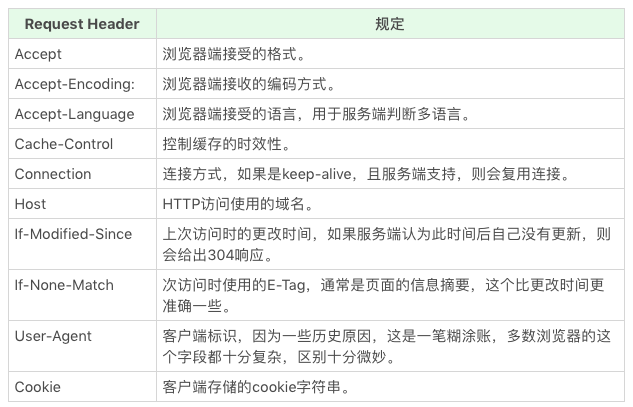 接下来看下Response Header:
接下来看下Response Header:
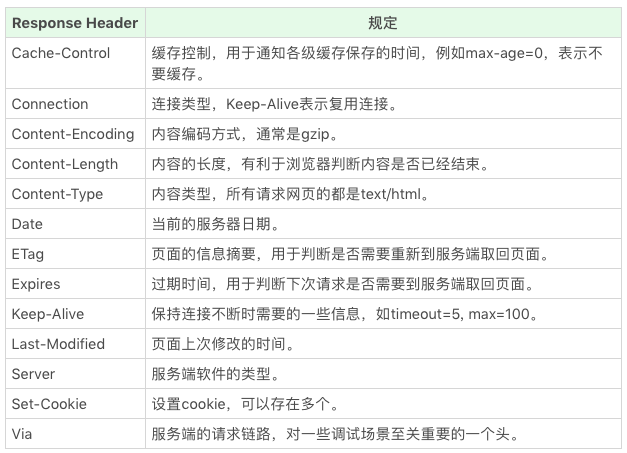
上方仅仅列出了常用的HTTP头,完整列表可在rfc2616中找到。
HTTP Request Body
HTTP请求的Body主要用于提交表单的场景。实际上HTTP请求的body是比较自由的,只要浏览器端发送的Body服务端认可就可以。一些常见的body格式:
- application/json
- application/x-www-form-urlencoded
- multipart/form-data
- text/xml
HTTPS
在HTTP协议的基础上,HTTPS和HTTP2规定了更复杂的内容,但是它基本保持了HTTP的设计思想,即:Request-Response模式。
HTTPS有两个作用,一是确定请求的目标服务器身份,二是保证传输的数据不会被网络中间节点窃听或篡改。
HTTPS相关标准链接:RFC 2818 - HTTP Over TLS HTTPS使用加密通道传输HTTP的内容,但是HTTP首先与服务器建立一条TLS加密通道。TLS构建于TCP协议之上,它实际上是对传输内容作了一次加密,所以从传输内容上看,HTTPS和HTTP没有任何区别。
HTTP2
HTTP2是对HTTP1.1的升级,相关标准参考:RFC 7540 - Hypertext Transfer Protocol Version 2 (HTTP/2)
HTTP2.0最大的改进有2点,一是支持服务端推送,二是支持TCP连接复用。
服务端推送能够在客户端发送第一个请求到服务端时,提前把一部分内容推送给客户端,放入缓存中。可以避免客户端请求顺序带来的并行度不高导致的性能问题。 TCP连接复用,则使用同一个TCP连接来传输多个HTTP请求,避免了TCP连接建立时的3次握手开销,和初建TCP连接时传输窗口小的问题。
构建DOM树🌲
通过HTTP请求返回了网页的HTML内容,接下来介绍如何解析HTML代码,DOM树又如何构建。
DOM 树描述了文档的内容。<html>元素是第一个标签也是文档树的根节点。树反映了不同标记之间的关系和层次结构。嵌套在其他标记中的标记是子节点。DOM 节点的数量越多,构建 DOM 树所需的时间就越长。
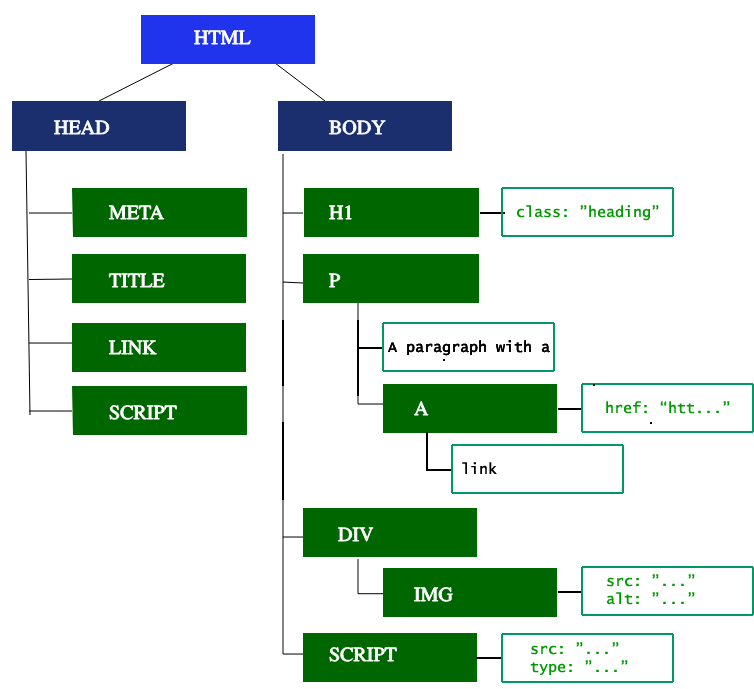
HTML的结构并不算太复杂,日常开发需要的“词”(编译原理中的token,表示最小有意义的单元),种类大约只有标签开始、属性、标签结束、注释、CDATA节点几种。
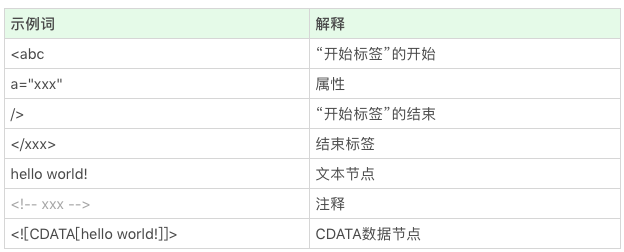
浏览器从HTTP协议收到的字符流读取字符。每输入一个字符,都要做一个决策,判断当前节点类型与操作,浏览器工程师常用状态机实现将字符流解析为词。
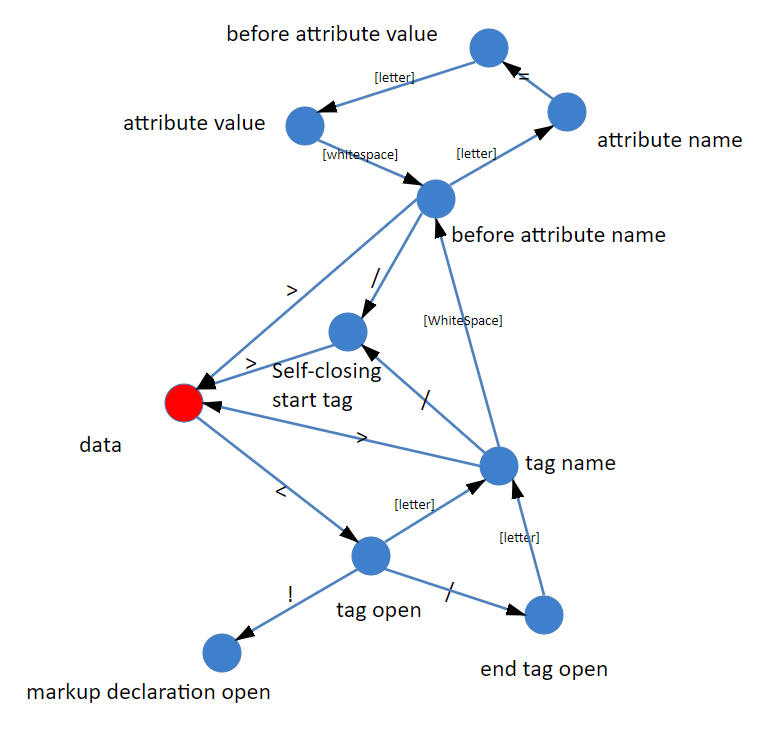 HTML官方文档规定了80多个状态,用状态机做词法分析,其实就是把每个词的特征字符逐个拆开成独立状态,然后再把所有词的特征字符链合并起来,形成连通图结构。
HTML官方文档规定了80多个状态,用状态机做词法分析,其实就是把每个词的特征字符逐个拆开成独立状态,然后再把所有词的特征字符链合并起来,形成连通图结构。
接下来要把这些简单的词构建为DOM树,这个过程用栈来实现:
function HTMLSyntaticalParser(){
var stack = [new HTMLDocument];
this.receiveInput = function(token) {
//……
}
this.getOutput = function(){
return stack[0];
}
}receiveInput负责接受词法部分产生的词,在接受的同时开始构建DOM树,当接收完所有输入,栈顶就是最后的根节点了,也就是DOM树的产出。在符合标准的浏览器中,不一样的HTML节点对应了不同的Node的子类。
大致流程如下:
- 栈顶元素就是当前节点
- 遇到属性,就添加到当前节点
- 遇到文本节点,如果当前是文本节点,则与文本节点合并,否则入栈作为当前节点的子节点
- 遇到注释节点,作为当前节点的子节点
- 遇到tag start就入栈一个节点,当前节点还是这个节点的父节点
- 遇到tag end就出栈一个节点(还可以检查是否匹配)
构建CSSOM树🌲
CSS 对象模型 (CSSOM) 是树形式的所有 CSS 选择器和每个选择器的相关属性的映射,具有树的根节点,同级,后代,子级和其他关系。CSSOM 与文档对象模型 (DOM)非常相似。两者都是关键渲染路径的一部分,也是正确渲染一个网站必须采取的一系列步骤。
CSSOM 与 DOM 一起构建渲染树,浏览器依次使用渲染树来布局和绘制网页。
CSS 有其自身的规则集合用来定义标识。注意 CSS 中的 C 代表的是“层叠”。CSS 规则是级联的。随着解析器转换标识为节点,节点的后代继承了样式。像处理 HTML 那样的增量处理功能没有被应用到 CSS 上,因为后续规则可能被之前的所覆盖。CSS 对象模型随着 CSS 的解析而被构建,但是直到完成都不能被用来构建渲染树,因为样式将会被之后的解析所覆盖而不应该被渲染到屏幕上。
其他过程
JavaScript编译
当 CSS 被解析并创建 CSSOM 时,其他资源,包括 JavaScript 文件正在下载(借助预加载扫描器)。JavaScript 被解释、编译、解析和执行。脚本被解析为抽象语法树。一些浏览器引擎使用抽象语法树(AST)并将其传递到解释器中,输出在主线程上执行的字节码。这就是所谓的 JavaScript 编译。
构建辅助功能树🌲
浏览器还构建辅助设备用于分析和解释内容的辅助功能(accessibility)树。无障碍对象模型(AOM)类似于 DOM 的语义版本。当 DOM 更新时,浏览器会更新辅助功能树。辅助技术本身无法修改无障碍树。
在构建 AOM 之前,屏幕阅读器无法访问内容。
渲染
渲染步骤包括样式、布局、绘制,在某些情况下还包括合成。在解析步骤中创建的 CSSOM 树和 DOM 树组合成一个 Render 树,然后用于计算每个可见元素的布局,然后将其绘制到屏幕上。在某些情况下,可以将内容提升到它们自己的层并进行合成,通过在 GPU 而不是 CPU 上绘制屏幕的一部分来提高性能,从而释放主线程。
构建Render树🌲
接下来将 DOM 和 CSSOM 组合成一个 Render 树,计算样式树或渲染树从 DOM 树的根开始构建,遍历每个可见节点。
像<head>和它的子节点以及任何具有 display: none 样式的结点,例如 script { display: none; }(在 user agent stylesheets 可以看到这个样式)这些标签将不会显示,也就是它们不会出现在 Render 树上。具有 visibility: hidden 的节点会出现在 Render 树上,因为它们会占用空间。
每个可见节点都应用了其 CSSOM 规则。Render 树保存所有具有内容和计算样式的可见节点——将所有相关样式匹配到 DOM 树中的每个可见节点,并根据CSS 级联确定每个节点的计算样式。
Layout
接下来在渲染树上运行布局以计算每个节点的几何体。布局是确定呈现树中所有节点的宽度、高度和位置,以及确定页面上每个对象的大小和位置的过程。回流是对页面的任何部分或整个文档的任何后续大小和位置的确定。
构建渲染树后,开始布局。渲染树标识显示哪些节点(即使不可见)及其计算样式,但不标识每个节点的尺寸或位置。为了确定每个对象的确切大小和位置,浏览器从渲染树的根开始遍历它。
在网页上,大多数东西都是一个盒子。不同的设备和不同的桌面意味着无限数量的不同的视区大小。在此阶段,考虑到视区大小,浏览器将确定屏幕上所有不同框的尺寸。以视区的大小为基础,布局通常从 body 开始,用每个元素的框模型属性排列所有 body 的子孙元素的尺寸,为不知道其尺寸的替换元素(例如图像)提供占位符空间。
第一次确定节点的大小和位置称为布局。随后对节点大小和位置的重新计算称为回流。假设初始布局发生在返回图像之前,若我们没有提前声明图像的大小,一旦确定了图像大小,就会有回流。
Paint
最后一步是将各个节点绘制到屏幕上,第一次出现的节点称为first meaningful paint。在绘制或光栅化阶段,浏览器将在布局阶段计算的每个框转换为屏幕上的实际像素。绘画包括将元素的每个可视部分绘制到屏幕上,包括文本、颜色、边框、阴影和替换的元素(如按钮和图像)。浏览器需要非常快地完成这项工作。
绘制可以将布局树中的元素分解为多个层。将内容提升到 GPU 上的层(而不是 CPU 上的主线程)可以提高绘制和重新绘制性能。有一些特定的属性和元素可以实例化一个层,包括 <video> 和 <canvas>,任何 CSS 属性为 opacity、3D transform、will-change的元素,还有一些其他元素。这些节点将与子节点一起绘制到它们自己的层上,除非子节点由于上述一个(或多个)原因需要自己的层。
Compositing
当文档的各个部分以不同的层绘制,相互重叠时,必须进行合成,以确保它们以正确的顺序绘制到屏幕上,并正确显示内容。
当页面继续加载资源时,可能会发生回流(例如加载图片资源),回流会触发重新绘制和重新组合。例如,如果我们定义了图像的大小,就不需要重新绘制,只需要重新绘制需要重新绘制的层,并在必要时进行合成。若未设置图像大小,从服务器获取图像后,渲染过程将返回到布局步骤并从那里重新开始。
Interactivity
一旦主线程绘制页面完成,可以认为已经“准备好了”,但事实并非如此。如果加载包含 JavaScript(并且延迟到onload事件激发后执行),则主线程可能很忙,无法用于滚动、触摸和其他交互。
TTI(Time to Interactivity)是测量从第一个请求导致 DNS 查询和 SSL 连接到页面可交互时所用的时间(可交互是First Contentful Paint之后的时间点)。如果主线程正在解析、编译和执行 JavaScript,则它不可用,因此无法及时(小于 50ms)响应用户交互。